|
|
||
|---|---|---|
| doc | ||
| src | ||
| test | ||
| .gitignore | ||
| Dockerfile | ||
| LICENSE | ||
| README.md | ||
README.md
docker-volume-backup
Docker image for performing simple backups of Docker volumes. Main features:
- Mount volumes into the container, and they'll get backed up
- Use full
cronexpressions for scheduling the backups - Backs up to local disk, AWS S3, or both
- Optionally stops containers for the duration of the backup, and starts them again afterward, to ensure consistent backups
- Optionally stops sevices for the duration of the backup, and starts them again afterward, to ensure consistent backups
- Optionally
docker execs commands before/after backing up a container, to allow easy integration with database backup tools, for example - Optionally exec any command(s) before scaling down/after scaling up services
- Optionally ships backup metrics to InfluxDB, for monitoring
Examples
Backing up locally
Say you're running some dashboards with Grafana and want to back them up:
version: "3"
services:
dashboard:
image: grafana/grafana:5.3.4
volumes:
- grafana-data:/var/lib/grafana # This is where Grafana keeps its data
backup:
image: futurice/docker-volume-backup:2.0.0
volumes:
- grafana-data:/backup/grafana-data:ro # Mount the Grafana data volume (as read-only)
- ./backups:/archive # Mount a local folder as the backup archive
volumes:
grafana-data:
This will back up the Grafana data volume, once per day, and write it to ./backups with a filename like backup-2018-11-27T16-51-56.tar.gz.
Backing up to S3
Off-site backups are better, though:
version: "3"
services:
dashboard:
image: grafana/grafana:5.3.4
volumes:
- grafana-data:/var/lib/grafana # This is where Grafana keeps its data
backup:
image: futurice/docker-volume-backup:2.0.0
environment:
AWS_S3_BUCKET_NAME: my-backup-bucket # S3 bucket which you own, and already exists
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID} # Read AWS secrets from environment (or a .env file)
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
volumes:
- grafana-data:/backup/grafana-data:ro # Mount the Grafana data volume (as read-only)
volumes:
grafana-data:
This configuration will back up to AWS S3 instead. See below for additional tips about S3 Bucket setup.
Stopping containers while backing up
It's not generally safe to read files to which other processes might be writing. You may end up with corrupted copies.
You can give the backup container access to the Docker socket, and label any containers that need to be stopped while the backup runs:
version: "3"
services:
dashboard:
image: grafana/grafana:5.3.4
volumes:
- grafana-data:/var/lib/grafana # This is where Grafana keeps its data
labels:
# Adding this label means this container should be stopped while it's being backed up:
- "docker-volume-backup.stop-during-backup=true"
backup:
image: futurice/docker-volume-backup:2.0.0
environment:
AWS_S3_BUCKET_NAME: my-backup-bucket # S3 bucket which you own, and already exists
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID} # Read AWS secrets from environment (or a .env file)
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro # Allow use of the "stop-during-backup" feature
- grafana-data:/backup/grafana-data:ro # Mount the Grafana data volume (as read-only)
volumes:
grafana-data:
This configuration allows you to safely back up things like databases, if you can tolerate a bit of downtime.
Pre/post backup exec
If you don't want to stop the container while it's being backed up, and the container comes with a backup utility (this is true for most databases), you can label the container with commands to run before/after backing it up:
version: "3"
services:
database:
image: influxdb:1.5.4
volumes:
- influxdb-data:/var/lib/influxdb # This is where InfluxDB keeps its data
- influxdb-temp:/tmp/influxdb # This is our temp space for the backup
labels:
# These commands will be exec'd (in the same container) before/after the backup starts:
- docker-volume-backup.exec-pre-backup=influxd backup -portable /tmp/influxdb
- docker-volume-backup.exec-post-backup=rm -rfv /tmp/influxdb
backup:
image: futurice/docker-volume-backup:2.0.0
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro # Allow use of the "pre/post exec" feature
- influxdb-temp:/backup/influxdb:ro # Mount the temp space so it gets backed up
- ./backups:/archive # Mount a local folder as the backup archive
volumes:
influxdb-data:
influxdb-temp:
The above configuration will perform a docker exec for the database container with influxd backup, right before the backup runs. The resulting DB snapshot is written to a temp volume (influxdb-temp), which is then backed up. Note that the main InfluxDB data volume (influxdb-data) isn't used at all, as it'd be unsafe to read while the DB process is running.
Similarly, after the temp volume has been backed up, it's cleaned up with another docker exec in the database container, this time just invoking rm.
If you need a more complex script for pre/post exec, consider mounting and invoking a shell script instead.
Configuration
| Variable | Default | Notes |
|---|---|---|
BACKUP_SOURCES |
/backup |
Where to read data from. This can be a space-separated list if you need to back up multiple paths, when mounting multiple volumes for example. On the other hand, you can also just mount multiple volumes under /backup to have all of them backed up. |
BACKUP_CRON_EXPRESSION |
@daily |
Standard debian-flavored cron expression for when the backup should run. Use e.g. 0 4 * * * to back up at 4 AM every night. See the man page or crontab.guru for more. |
BACKUP_FILENAME |
backup-%Y-%m-%dT%H-%M-%S.tar.gz |
File name template for the backup file. Is passed through date for formatting. See the man page for more. |
BACKUP_ARCHIVE |
/archive |
When this path is available within the container (i.e. you've mounted a Docker volume there), a finished backup file will get archived there after each run. |
BACKUP_WAIT_SECONDS |
0 |
The backup script will sleep this many seconds between re-starting stopped containers, and proceeding with archiving/uploading the backup. This can be useful if you don't want the load/network spike of a large upload immediately after the load/network spike of container startup. |
BACKUP_HOSTNAME |
$(hostname) |
Name of the host (i.e. Docker container) in which the backup runs. Mostly useful if you want a specific hostname to be associated with backup metrics (see InfluxDB support). |
AWS_S3_BUCKET_NAME |
When provided, the resulting backup file will be uploaded to this S3 bucket after the backup has ran. | |
AWS_ACCESS_KEY_ID |
Required when using AWS_S3_BUCKET_NAME. |
|
AWS_SECRET_ACCESS_KEY |
Required when using AWS_S3_BUCKET_NAME. |
|
AWS_DEFAULT_REGION |
Optional when using AWS_S3_BUCKET_NAME. Allows you to override the AWS CLI default region. Usually not needed. |
|
INFLUXDB_URL |
When provided, backup metrics will be sent to an InfluxDB instance at this URL, e.g. https://influxdb.example.com. |
|
INFLUXDB_DB |
Required when using INFLUXDB_URL; e.g. my_database. |
|
INFLUXDB_CREDENTIALS |
Required when using INFLUXDB_URL; e.g. user:pass. |
|
INFLUXDB_MEASUREMENT |
docker_volume_backup |
Required when using INFLUXDB_URL. |
Metrics
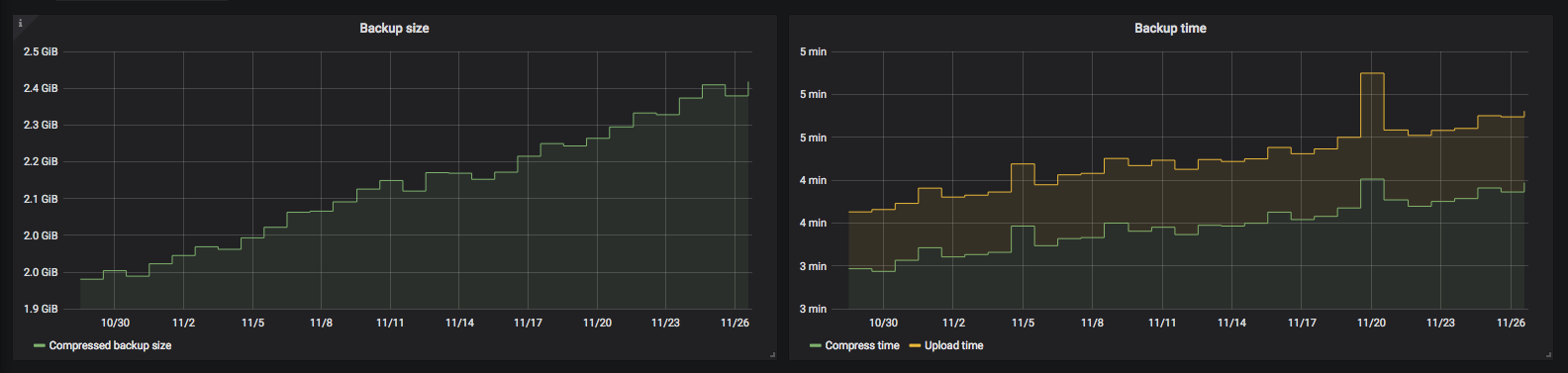
After the backup, the script will collect some metrics from the run. By default, they're just written out as logs. For example:
docker_volume_backup
host=my-demo-host
size_compressed_bytes=219984
containers_total=4
containers_stopped=1
time_wall=61.6939337253571
time_total=1.69393372535706
time_compress=0.171068429946899
time_upload=0.56016993522644
If so configured, they can also be shipped to an InfluxDB instance. This allows you to set up monitoring and/or alerts for them. Here's a sample visualization on Grafana:
S3 Bucket setup
Amazon S3 has Versioning and Object Lifecycle Management features that can be useful for backups.
First, you can enable versioning for your backup bucket:
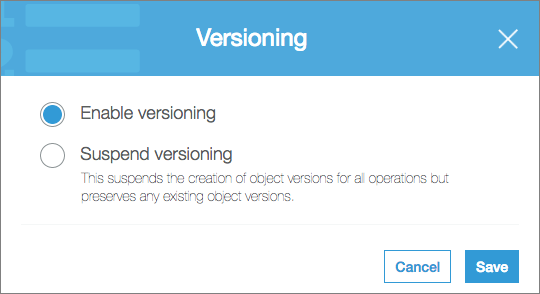
Then, you can change your backup filename to a static one, for example:
environment:
BACKUP_FILENAME: latest.tar.gz
This allows you to retain previous versions of the backup file, but the most recent version is always available with the same filename:
$ aws s3 cp s3://my-backup-bucket/latest.tar.gz .
download: s3://my-backup-bucket/latest.tar.gz to ./latest.tar.gz
To make sure your bucket doesn't continue to grow indefinitely, you can enable some lifecycle rules:
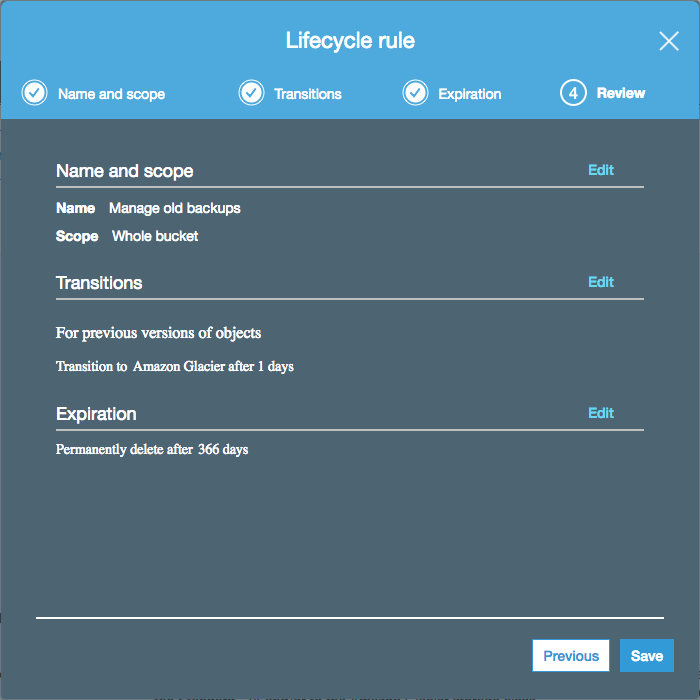
These rules will:
- Move non-latest backups to a cheaper, long-term storage class (Glacier)
- Permanently remove backups after a year
- Still always keep the latest backup available (even after a year has passed)
Testing
A bunch of test cases exist under test. To run them:
cd test/backing-up-locally/
docker-compose stop && docker-compose rm -f && docker-compose build && docker-compose up
Some cases may need secrets available in the environment, e.g. for S3 uploads to work.
Building
New images can be conveniently built on Docker Hub. Update the tag name, save, and use the "Trigger" button: