Signed-off-by: Jacob Torrey <jacob@thinkst.com> |
||
|---|---|---|
| .github/workflows | ||
| inch | ||
| nlzmadetect | ||
| samples | ||
| .gitignore | ||
| .gitmodules | ||
| LICENSE | ||
| README.md | ||
| ai-generated.txt | ||
| ai_detect_roc.png | ||
| burstiness.py | ||
| crossplag-report.xml | ||
| crossplag_detect.py | ||
| gptzero-report.xml | ||
| gptzero_detect.py | ||
| openai-report.xml | ||
| openai_detect.py | ||
| plot_rocs.py | ||
| roberta-report.xml | ||
| roberta_detect.py | ||
| roberta_local.py | ||
| test_crossplag_detect.py | ||
| test_gptzero_detect.py | ||
| test_openai_detect.py | ||
| test_roberta_detect.py | ||
| test_zippy_detect.py | ||
| zippy-report.xml | ||
| zippy.py | ||
{kind=link}
README.md
ZipPy: Fast method to classify text as AI or human-generated
This is a research repo for fast AI detection using compression. While there are a number of existing LLM detection systems, they all use a large model trained on either an LLM or its training data to calculate the probability of each word given the preceeding, then calculating a score where the more high-probability tokens are more likely to be AI-originated. Techniques and tools in this repo are looking for faster approximation to be embeddable and more scalable.
LZMA compression detector (zippy.py and nlzmadetect)
ZipPy uses the LZMA compression ratios as a way to indirectly measure the perplexity of a text.
Compression ratios have been used in the past to detect anomalies in network data
for intrusion detection, so if perplexity is roughly a measure of anomalous tokens, it may be possible to use compression to detect low-perplexity text.
LZMA creates a dictionary of seen tokens, and then uses though in place of future tokens. The dictionary size, token length, etc.
are all dynamic (though influenced by the 'preset' of 0-9--with 0 being the fastest but worse compression than 9). The basic idea
is to 'seed' an LZMA compression stream with a corpus of AI-generated text (ai-generated.txt) and then measure the compression ratio of
just the seed data with that of the sample appended. Samples that follow more closely in word choice, structure, etc. will acheive a higher
compression ratio due to the prevalence of similar tokens in the dictionary, novel words, structures, etc. will appear anomalous to the seeded
dictionary, resulting in a worse compression ratio.
Current evaluation
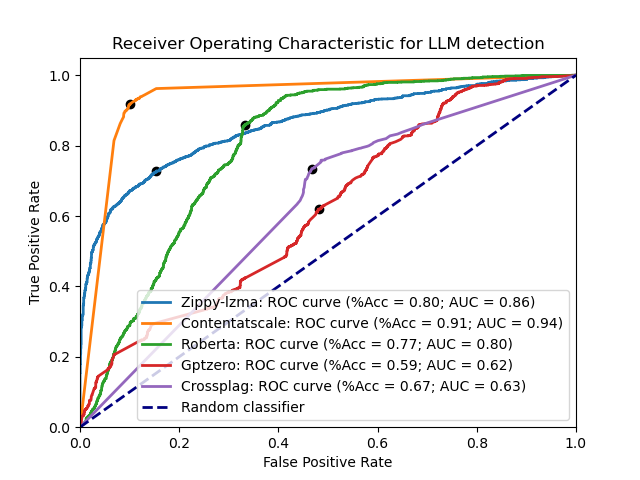
Some of the leading LLM detection tools are OpenAI's model detector (v2), GPTZero, CrossPlag's AI detector, and Roberta. Here are each of them compared with the LZMA detector across the test datasets:
Usage
ZipPy will read files passed as command-line arguments, or will read from stdin to allow for piping of text to it.
$ python3 zippy.py -h
usage: zippy.py [-h] [-s | sample_files ...]
positional arguments:
sample_files Text file(s) containing the sample to classify
options:
-h, --help show this help message and exit
-s Read from stdin until EOF is reached instead of from a file
$ python3 zippy.py samples/human-generated/about_me.txt
samples/human-generated/about_me.txt
('Human', 0.06013429262166636)