kopia lustrzana https://github.com/thinkst/zippy
Update README to reflect zlib and contentatscale.ai
Signed-off-by: Jacob Torrey <jacob@thinkst.com>pull/6/head
rodzic
1e3ae4e9aa
commit
2954176173
21
README.md
21
README.md
|
|
@ -6,21 +6,23 @@ its training data to calculate the probability of each word given the preceeding
|
|||
the more high-probability tokens are more likely to be AI-originated. Techniques and tools in this repo are looking for
|
||||
faster approximation to be embeddable and more scalable.
|
||||
|
||||
## LZMA compression detector (`zippy.py` and `nlzmadetect`)
|
||||
## Compression-based detector (`zippy.py` and `nlzmadetect`)
|
||||
|
||||
ZipPy uses the LZMA compression ratios as a way to indirectly measure the perplexity of a text.
|
||||
ZipPy uses either the LZMA or zlib compression ratios as a way to indirectly measure the perplexity of a text.
|
||||
Compression ratios have been used in the past to [detect anomalies in network data](http://owncloud.unsri.ac.id/journal/security/ontheuse_compression_Network_anomaly_detec.pdf)
|
||||
for intrusion detection, so if perplexity is roughly a measure of anomalous tokens, it may be possible to use compression to detect low-perplexity text.
|
||||
LZMA creates a dictionary of seen tokens, and then uses though in place of future tokens. The dictionary size, token length, etc.
|
||||
LZMA and zlib creates a dictionary of seen tokens, and then uses though in place of future tokens. The dictionary size, token length, etc.
|
||||
are all dynamic (though influenced by the 'preset' of 0-9--with 0 being the fastest but worse compression than 9). The basic idea
|
||||
is to 'seed' an LZMA compression stream with a corpus of AI-generated text (`ai-generated.txt`) and then measure the compression ratio of
|
||||
is to 'seed' a compression stream with a corpus of AI-generated text (`ai-generated.txt`) and then measure the compression ratio of
|
||||
just the seed data with that of the sample appended. Samples that follow more closely in word choice, structure, etc. will acheive a higher
|
||||
compression ratio due to the prevalence of similar tokens in the dictionary, novel words, structures, etc. will appear anomalous to the seeded
|
||||
dictionary, resulting in a worse compression ratio.
|
||||
|
||||
### Current evaluation
|
||||
|
||||
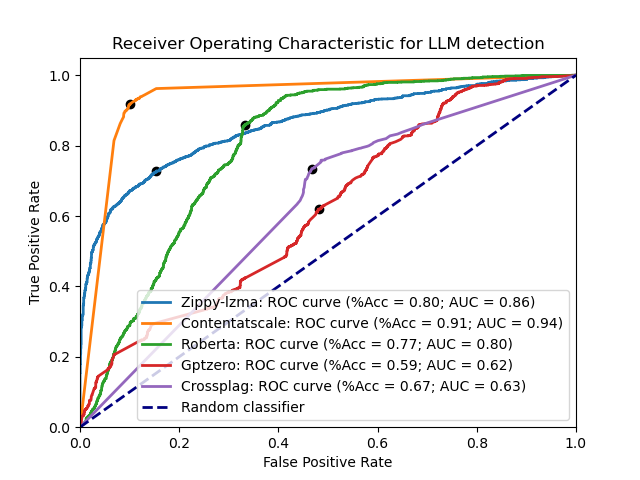
Some of the leading LLM detection tools are ~~[OpenAI's model detector (v2)](https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text)~~, [GPTZero](https://gptzero.me/), [CrossPlag's AI detector](https://crossplag.com/ai-content-detector/), and [Roberta](https://huggingface.co/roberta-base-openai-detector). Here are each of them compared with the LZMA detector across the test datasets:
|
||||
Some of the leading LLM detection tools are:
|
||||
~~[OpenAI's model detector (v2)](https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text)~~, [Content at Scale](https://contentatscale.ai/ai-content-detector/), [GPTZero](https://gptzero.me/), [CrossPlag's AI detector](https://crossplag.com/ai-content-detector/), and [Roberta](https://huggingface.co/roberta-base-openai-detector).
|
||||
Here are each of them compared with both the LZMA and zlib detector across the test datasets:
|
||||
|
||||
|
||||
|
||||
|
|
@ -29,14 +31,15 @@ Some of the leading LLM detection tools are ~~[OpenAI's model detector (v2)](htt
|
|||
ZipPy will read files passed as command-line arguments, or will read from stdin to allow for piping of text to it.
|
||||
```
|
||||
$ python3 zippy.py -h
|
||||
usage: zippy.py [-h] [-s | sample_files ...]
|
||||
usage: zippy.py [-h] [-e {zlib,lzma}] [-s | sample_files ...]
|
||||
|
||||
positional arguments:
|
||||
sample_files Text file(s) containing the sample to classify
|
||||
sample_files Text file(s) containing the sample to classify
|
||||
|
||||
options:
|
||||
-h, --help show this help message and exit
|
||||
-s Read from stdin until EOF is reached instead of from a file
|
||||
-h, --help show this help message and exit
|
||||
-e {zlib,lzma} Which compression engine to use: lzma or zlib
|
||||
-s Read from stdin until EOF is reached instead of from a file
|
||||
$ python3 zippy.py samples/human-generated/about_me.txt
|
||||
samples/human-generated/about_me.txt
|
||||
('Human', 0.06013429262166636)
|
||||
|
|
|
|||
Ładowanie…
Reference in New Issue