kopia lustrzana https://github.com/kartoza/docker-postgis
Merge branch 10 into develop (#113)
* Fix typo in helper script * Port work in develop to 10 branch (#90) * Port 9.6 to develop (#89) * Part one of porting work from 9.6 to 10 * Backported more scripts from 9.6 branch * Added missing apt update in dockerfile * Updates to entrypoint to reference image and update docker-compose to reference 10 pg * Added sample and docs from 9.6 branch * Removed my diagram as Rizky had already added one * Fix env paths for pg 10 * Fixes for backporting work from 9.6 to 10 - dbb now spins up and accepts connections properly * Update README.md * Backport from branch: 9.6-2.4 Fix default datadir - Change into default datadir - Add small unittest * Optimise PostgreSQL performance and align with the changes done in 9.6 version * Fix version numbers * Minor change to correct env file * Merged 10 branch into develop * Remove reduntant conf file from dockerfile * Remove reduntant conf file directive from setup script * Remove reduntant conf file directive from scriptpull/114/head
rodzic
6f30fba235
commit
f99cb9f438
|
|
@ -35,11 +35,7 @@ ADD setup-pg_hba.sh /
|
|||
ADD setup-replication.sh /
|
||||
ADD setup-ssl.sh /
|
||||
ADD setup-user.sh /
|
||||
ADD postgresql.conf /tmp/postgresql.conf
|
||||
RUN chmod +x /docker-entrypoint.sh
|
||||
|
||||
# Optimise postgresql
|
||||
RUN echo "kernel.shmmax=543252480" >> /etc/sysctl.conf
|
||||
RUN echo "kernel.shmall=2097152" >> /etc/sysctl.conf
|
||||
|
||||
ENTRYPOINT /docker-entrypoint.sh
|
||||
|
|
|
|||
88
README.md
88
README.md
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
A simple docker container that runs PostGIS
|
||||
|
||||
Visit our page on the docker hub at: https://registry.hub.docker.com/u/kartoza/postgis/
|
||||
Visit our page on the docker hub at: https://hub.docker.com/r/kartoza/postgis/
|
||||
|
||||
There are a number of other docker postgis containers out there. This one
|
||||
differentiates itself by:
|
||||
|
|
@ -14,14 +14,12 @@ differentiates itself by:
|
|||
* template_postgis database template is created for you
|
||||
* a default database 'gis' is created for you so you can use this container 'out of the
|
||||
box' when it runs with e.g. QGIS
|
||||
* supports single master replication
|
||||
* replication support included
|
||||
|
||||
We will work to add more security features to this container in the future with
|
||||
the aim of making a PostGIS image that is ready to be used in a production
|
||||
environment (though probably not for heavy load databases).
|
||||
|
||||
## Tutorial
|
||||
|
||||
There is a nice 'from scratch' tutorial on using this docker image on Alex Urquhart's
|
||||
blog [here](https://alexurquhart.com/post/set-up-postgis-with-docker/) - if you are
|
||||
just getting started with docker, PostGIS and QGIS, we really recommend that you use it.
|
||||
|
|
@ -62,7 +60,7 @@ since deb packages need to be refetched each time you build) do:
|
|||
docker build -t kartoza/postgis git://github.com/kartoza/docker-postgis
|
||||
```
|
||||
|
||||
To build with apt-cache (and minimised download requirements) do you need to
|
||||
To build with apt-cacher (and minimise download requirements) you need to
|
||||
clone this repo locally first and modify the contents of 71-apt-cacher-ng to
|
||||
match your cacher host. Then build using a local url instead of directly from
|
||||
github.
|
||||
|
|
@ -102,7 +100,14 @@ user is set to 'docker' with password 'docker'.
|
|||
You can open up the PG port by using the following environment variable. By default
|
||||
the container will allow connections only from the docker private subnet.
|
||||
|
||||
* -e ALLOW_IP_RANGE=<0.0.0.0/0>
|
||||
* -e ALLOW_IP_RANGE=<0.0.0.0/0> By default
|
||||
t
|
||||
|
||||
Postgres conf is setup to listen to all connections and if a user needs to restrict which IP address
|
||||
PostgreSQL listens to you can define it with the following environment variable. The default is set to listen to
|
||||
all connections.
|
||||
* -e IP_LIST=<*>
|
||||
|
||||
|
||||
|
||||
## Convenience docker-compose.yml
|
||||
|
|
@ -137,10 +142,10 @@ psql -h localhost -U docker -p 25432 -l
|
|||
|
||||
You can then go on to use any normal postgresql commands against the container.
|
||||
|
||||
Under ubuntu 14.04 the postgresql client can be installed like this:
|
||||
Under ubuntu 16.04 the postgresql client can be installed like this:
|
||||
|
||||
```
|
||||
sudo apt-get install postgresql-client-9.5
|
||||
sudo apt-get install postgresql-client-9.6
|
||||
```
|
||||
|
||||
|
||||
|
|
@ -163,55 +168,55 @@ Replication allows you to maintain two or more synchronised copies of a database
|
|||
single **master** copy and one or more **replicant** copies. The animation below illustrates
|
||||
this - the layer with the red boundary is accessed from the master database and the layer
|
||||
with the green fill is accessed from the replicant database. When edits to the master
|
||||
layer are saved, they are automatically propogated to the replicant. Note also that the
|
||||
layer are saved, they are automatically propagated to the replicant. Note also that the
|
||||
replicant is read-only.
|
||||
|
||||
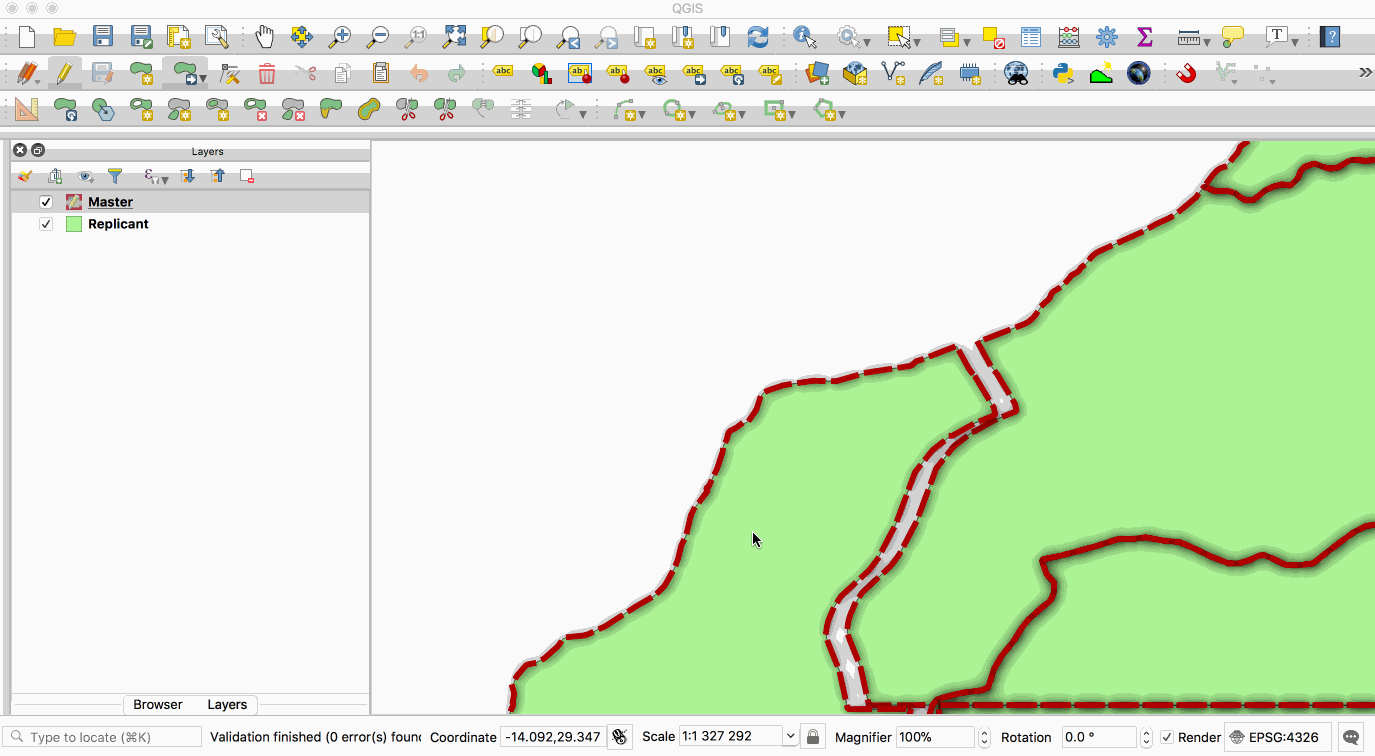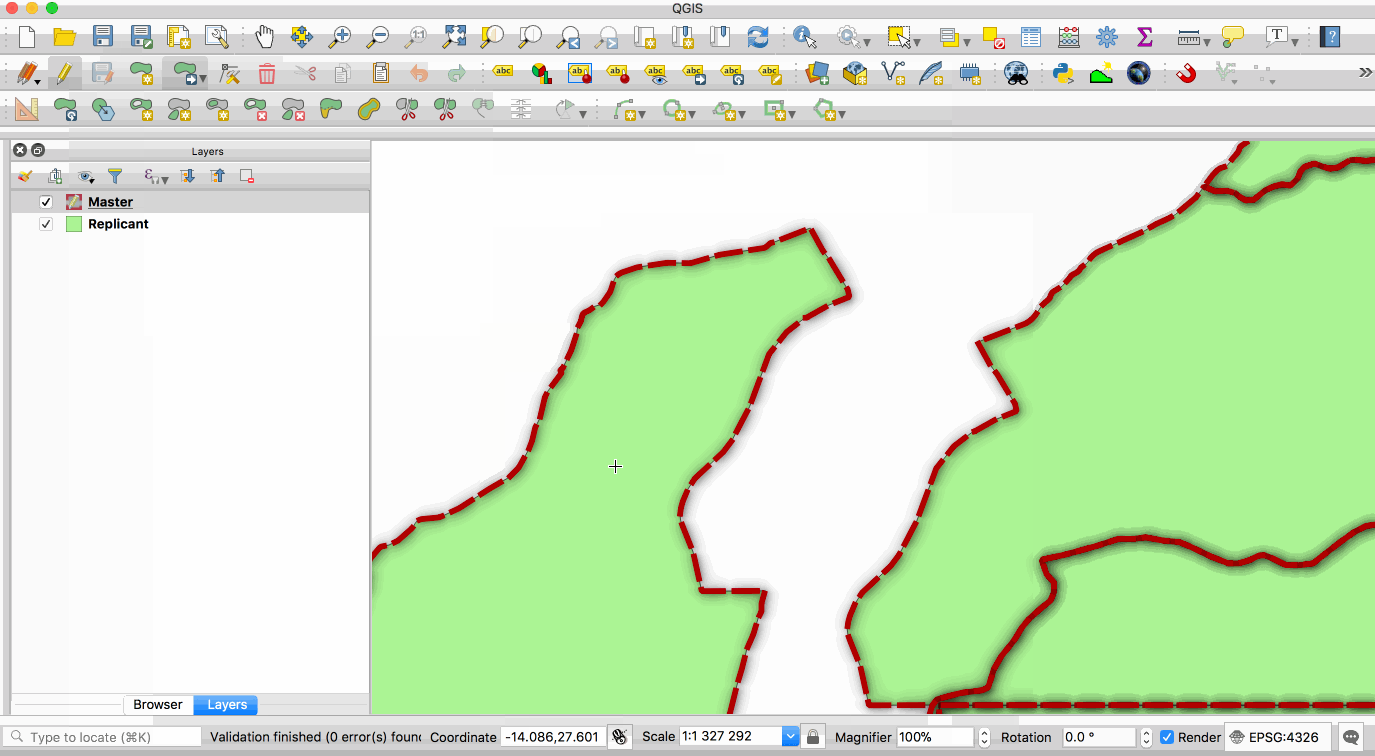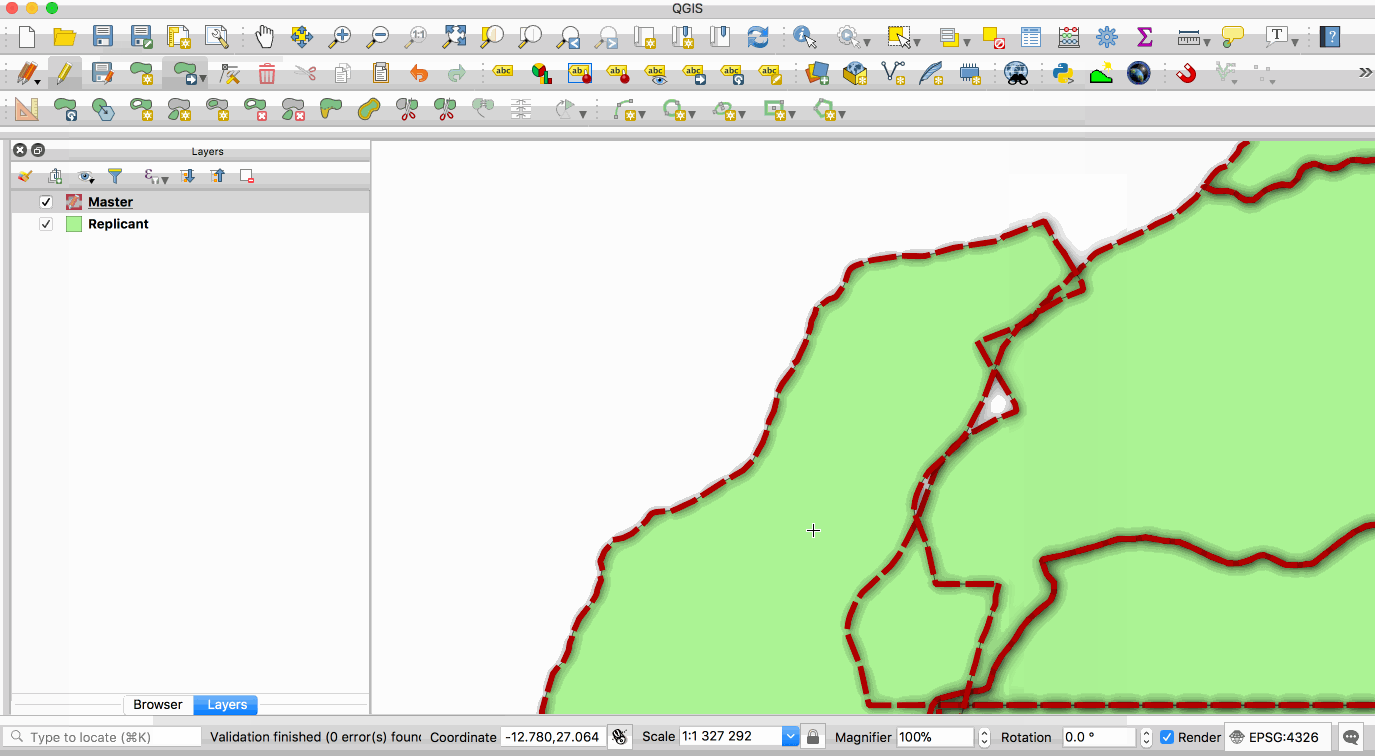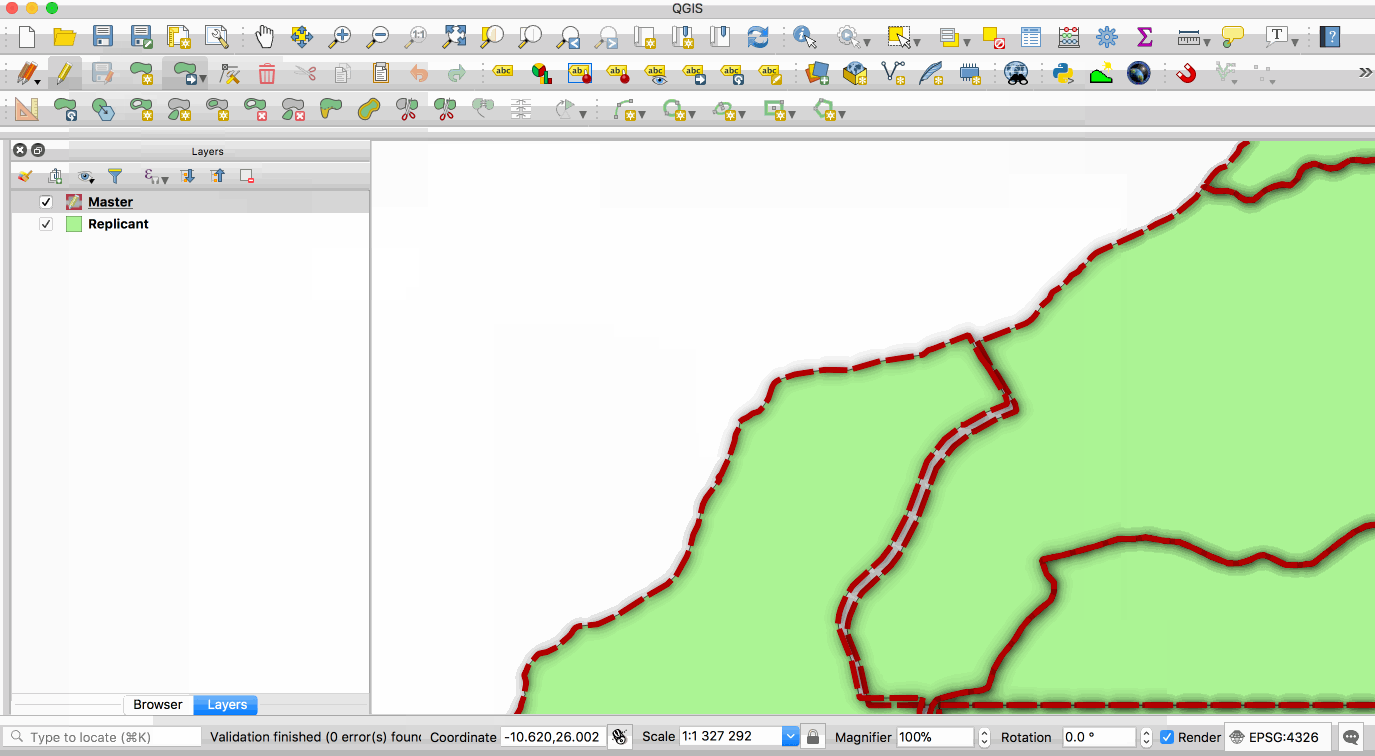
|
||||
|
||||
This image is provided with replication abilities. We can
|
||||
categorize an instance of the container as `master` or `replicant`. A `master`
|
||||
instance means that a particular container have a role as a single point of
|
||||
instance means that a particular container has a role as a single point of
|
||||
database write. A `replicant` instance means that a particular container will
|
||||
mirror database content from a designated master. This replication scheme allows
|
||||
us to sync database. However a `replicant` is only of read-only transaction, thus
|
||||
we can't write new data on it.
|
||||
us to sync databases. However a `replicant` is only for read-only transaction, thus
|
||||
we can't write new data to it. The whole database cluster will be replicated.
|
||||
|
||||
To experiment with the replication abilities, you can see a (docker-compose.yml)[sample/replication/docker-compose.yml]
|
||||
sample provided. There are several environment variables that you can set, such as:
|
||||
sample. There are several environment variables that you can set, such as:
|
||||
|
||||
Master settings:
|
||||
- **ALLOW_IP_RANGE**: A pg_hba.conf domain format which will allow certain host
|
||||
to connect into the container. This is needed to allow `slave` to connect
|
||||
into `master`, so specifically this settings should allow `slave` address.
|
||||
- Both POSTGRES_USER and POSTGRES_PASS will be used as credentials for slave to
|
||||
connect, so make sure you changed this into something secure.
|
||||
- **ALLOW_IP_RANGE**: A pg_hba.conf domain format which will allow specified host(s)
|
||||
to connect into the container. This is needed to allow the `slave` to connect
|
||||
into `master`, so specifically this settings should allow `slave` address. It is also needed to allow clients on other hosts to connect to either the slave or the master.
|
||||
- Both POSTGRES_USER and POSTGRES_PASS will be used as credentials for the slave to
|
||||
connect, so make sure you change this into something secure.
|
||||
|
||||
Slave settings:
|
||||
- **REPLICATE_FROM**: This should be the domain name, or ip address of `master`
|
||||
instance. It can be anything from docker resolved name like written in the sample,
|
||||
- **REPLICATE_FROM**: This should be the domain name or IP address of the `master`
|
||||
instance. It can be anything from the docker resolved name like that written in the sample,
|
||||
or the IP address of the actual machine where you expose `master`. This is
|
||||
useful to create cross machine replication, or cross stack/server.
|
||||
- **REPLICATE_PORT**: This should be the port number of `master` postgres instance.
|
||||
Will default to 5432 (default postgres port), if not specified.
|
||||
- **DESTROY_DATABASE_ON_RESTART**: Default is `True`. Set to otherwise to prevent
|
||||
- **DESTROY_DATABASE_ON_RESTART**: Default is `True`. Set to 'False' to prevent
|
||||
this behaviour. A replicant will always destroy its current database on
|
||||
restart, because it will try to sync again from `master` and avoid inconsistencies.
|
||||
- **PROMOTE_MASTER**: Default none. If set to any value, then the current replicant
|
||||
- **PROMOTE_MASTER**: Default none. If set to any value then the current replicant
|
||||
will be promoted to master.
|
||||
In some cases when `master` container has failed, we might want to use our `replicant`
|
||||
as `master` for a while. However promoted replicant will break consistencies and
|
||||
is not able to revert to replicant anymore, unless the were destroyed and resynced
|
||||
In some cases when the `master` container has failed, we might want to use our `replicant`
|
||||
as `master` for a while. However, the promoted replicant will break consistencies and
|
||||
is not able to revert to replicant anymore, unless it is destroyed and resynced
|
||||
with the new master.
|
||||
|
||||
To run sample replication, do the following instructions:
|
||||
To run the sample replication, follow these instructions:
|
||||
|
||||
Do manual image build by executing `build.sh` script
|
||||
Do a manual image build by executing the `build.sh` script
|
||||
|
||||
```
|
||||
./build.sh
|
||||
```
|
||||
|
||||
Go into `sample/replication` directory and experiment with the following Make
|
||||
Go into the `sample/replication` directory and experiment with the following Make
|
||||
command to run both master and slave services.
|
||||
|
||||
```
|
||||
|
|
@ -237,7 +242,7 @@ You can try experiment with several scenarios to see how replication works
|
|||
|
||||
You can use any postgres database tools to create new tables in master, by
|
||||
connecting using POSTGRES_USER and POSTGRES_PASS credentials using exposed port.
|
||||
In the sample, master database were exposed in port 7777.
|
||||
In the sample, the master database was exposed on port 7777.
|
||||
Or you can do it via command line, by entering the shell:
|
||||
|
||||
```
|
||||
|
|
@ -246,8 +251,8 @@ make master-shell
|
|||
|
||||
Then made any database changes using psql.
|
||||
|
||||
After that, you can see that replicant follows the changes by inspecting
|
||||
slave database. You can, again, uses database management tools using connection
|
||||
After that, you can see that the replicant follows the changes by inspecting the
|
||||
slave database. You can, again, use database management tools using connection
|
||||
credentials, hostname, and ports for replicant. Or you can do it via command line,
|
||||
by entering the shell:
|
||||
|
||||
|
|
@ -259,27 +264,30 @@ Then view your changes using psql.
|
|||
|
||||
### Promoting replicant to master
|
||||
|
||||
You will notice that you cannot make changes in replicant, because it was read-only.
|
||||
You will notice that you cannot make changes in replicant, because it is read-only.
|
||||
If somehow you want to promote it to master, you can specify `PROMOTE_MASTER: 'True'`
|
||||
into slave environment and set `DESTROY_DATABASE_ON_RESTART: 'False'`.
|
||||
|
||||
After this, you can make changes to your replicant, but master and replicant will not
|
||||
be in sync anymore. This is useful if replicant needs to take over a failover master.
|
||||
However it was recommended to take additional action, such as creating backup from
|
||||
slave, so a dedicated master can be created again.
|
||||
be in sync anymore. This is useful if the replicant needs to take over a failover master.
|
||||
However it is recommended to take additional action, such as creating a backup from the
|
||||
slave so a dedicated master can be created again.
|
||||
|
||||
### Preventing replicant database destroy on restart
|
||||
|
||||
You can optionally set `DESTROY_DATABASE_ON_RESTART: 'False'` after successful sync
|
||||
to prevent the database from destroyed on restart. With this settings, you can
|
||||
shutdown your replicant and restart it later and it will continue to sync using existing
|
||||
database (as long as there is no consistencies conflicts).
|
||||
to prevent the database from being destroyed on restart. With this setting you can
|
||||
shut down your replicant and restart it later and it will continue to sync using the existing
|
||||
database (as long as there are no consistencies conflicts).
|
||||
|
||||
However, you should note that this option doesn't mean anything if you didn't
|
||||
persist your database volumes. Because if it is not persisted, then it will be lost
|
||||
persist your database volume. Because if it is not persisted, then it will be lost
|
||||
on restart because docker will recreate the container.
|
||||
|
||||
## Credits
|
||||
|
||||
Tim Sutton (tim@kartoza.com)
|
||||
May 2014
|
||||
Gavin Fleming (gavin@kartoza.com)
|
||||
Risky Maulana (rizky@kartoza.com)
|
||||
Admire Nyakudya (admire@kartoza.com)
|
||||
December 2018
|
||||
|
|
|
|||
1
build.sh
1
build.sh
|
|
@ -1,2 +1,3 @@
|
|||
#!/usr/bin/env bash
|
||||
docker build -t kartoza/postgis:manual-build .
|
||||
docker build -t kartoza/postgis:10.0-2.4 .
|
||||
|
|
|
|||
|
|
@ -40,13 +40,13 @@ done
|
|||
if [ $# -eq 0 ];
|
||||
then
|
||||
echo "Postgres initialisation process completed .... restarting in foreground"
|
||||
cat /tmp/postgresql.conf > ${CONF}
|
||||
|
||||
su - postgres -c "$SETVARS $POSTGRES -D $DATADIR -c config_file=$CONF"
|
||||
fi
|
||||
|
||||
# If arguments passed, run postgres with these arguments
|
||||
# This will make sure entrypoint will always be executed
|
||||
if [ "${1:0:1}" = '-' ]; then
|
||||
if [[ "${1:0:1}" = '-' ]]; then
|
||||
# append postgres into the arguments
|
||||
set -- postgres "$@"
|
||||
fi
|
||||
|
|
|
|||
|
|
@ -3,6 +3,7 @@
|
|||
DATADIR="/var/lib/postgresql/10/main"
|
||||
ROOT_CONF="/etc/postgresql/10/main"
|
||||
CONF="$ROOT_CONF/postgresql.conf"
|
||||
WAL_ARCHIVE="/opt/archivedir"
|
||||
RECOVERY_CONF="$ROOT_CONF/recovery.conf"
|
||||
POSTGRES="/usr/lib/postgresql/10/bin/postgres"
|
||||
INITDB="/usr/lib/postgresql/10/bin/initdb"
|
||||
|
|
@ -49,6 +50,9 @@ if [ -z "${PG_WAL_KEEP_SEGMENTS}" ]; then
|
|||
PG_WAL_KEEP_SEGMENTS=100
|
||||
fi
|
||||
|
||||
if [ -z "${IP_LIST}" ]; then
|
||||
IP_LIST='*'
|
||||
fi
|
||||
|
||||
# Compatibility with official postgres variable
|
||||
# Official postgres variable gets priority
|
||||
|
|
|
|||
652
postgresql.conf
652
postgresql.conf
|
|
@ -1,652 +0,0 @@
|
|||
# -----------------------------
|
||||
# PostgreSQL configuration file
|
||||
# -----------------------------
|
||||
#
|
||||
# This file consists of lines of the form:
|
||||
#
|
||||
# name = value
|
||||
#
|
||||
# (The "=" is optional.) Whitespace may be used. Comments are introduced with
|
||||
# "#" anywhere on a line. The complete list of parameter names and allowed
|
||||
# values can be found in the PostgreSQL documentation.
|
||||
#
|
||||
# The commented-out settings shown in this file represent the default values.
|
||||
# Re-commenting a setting is NOT sufficient to revert it to the default value;
|
||||
# you need to reload the server.
|
||||
#
|
||||
# This file is read on server startup and when the server receives a SIGHUP
|
||||
# signal. If you edit the file on a running system, you have to SIGHUP the
|
||||
# server for the changes to take effect, or use "pg_ctl reload". Some
|
||||
# parameters, which are marked below, require a server shutdown and restart to
|
||||
# take effect.
|
||||
#
|
||||
# Any parameter can also be given as a command-line option to the server, e.g.,
|
||||
# "postgres -c log_connections=on". Some parameters can be changed at run time
|
||||
# with the "SET" SQL command.
|
||||
#
|
||||
# Memory units: kB = kilobytes Time units: ms = milliseconds
|
||||
# MB = megabytes s = seconds
|
||||
# GB = gigabytes min = minutes
|
||||
# TB = terabytes h = hours
|
||||
# d = days
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# FILE LOCATIONS
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# The default values of these variables are driven from the -D command-line
|
||||
# option or PGDATA environment variable, represented here as ConfigDir.
|
||||
|
||||
data_directory = '/var/lib/postgresql/10/main' # use data in another directory
|
||||
# (change requires restart)
|
||||
hba_file = '/etc/postgresql/10/main/pg_hba.conf' # host-based authentication file
|
||||
# (change requires restart)
|
||||
ident_file = '/etc/postgresql/10/main/pg_ident.conf' # ident configuration file
|
||||
# (change requires restart)
|
||||
|
||||
# If external_pid_file is not explicitly set, no extra PID file is written.
|
||||
external_pid_file = '/var/run/postgresql/10-main.pid' # write an extra PID file
|
||||
# (change requires restart)
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# CONNECTIONS AND AUTHENTICATION
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Connection Settings -
|
||||
|
||||
#listen_addresses = 'localhost' # what IP address(es) to listen on;
|
||||
# comma-separated list of addresses;
|
||||
# defaults to 'localhost'; use '*' for all
|
||||
# (change requires restart)
|
||||
port = 5432 # (change requires restart)
|
||||
max_connections = 100 # (change requires restart)
|
||||
#superuser_reserved_connections = 3 # (change requires restart)
|
||||
unix_socket_directories = '/var/run/postgresql' # comma-separated list of directories
|
||||
# (change requires restart)
|
||||
#unix_socket_group = '' # (change requires restart)
|
||||
#unix_socket_permissions = 0777 # begin with 0 to use octal notation
|
||||
# (change requires restart)
|
||||
#bonjour = off # advertise server via Bonjour
|
||||
# (change requires restart)
|
||||
#bonjour_name = '' # defaults to the computer name
|
||||
# (change requires restart)
|
||||
|
||||
# - Security and Authentication -
|
||||
|
||||
#authentication_timeout = 1min # 1s-600s
|
||||
ssl = on # (change requires restart)
|
||||
#ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL' # allowed SSL ciphers
|
||||
# (change requires restart)
|
||||
#ssl_prefer_server_ciphers = on # (change requires restart)
|
||||
#ssl_ecdh_curve = 'prime256v1' # (change requires restart)
|
||||
ssl_cert_file = '/etc/ssl/certs/ssl-cert-snakeoil.pem' # (change requires restart)
|
||||
ssl_key_file = '/etc/ssl/private/ssl-cert-snakeoil.key' # (change requires restart)
|
||||
#ssl_ca_file = '' # (change requires restart)
|
||||
#ssl_crl_file = '' # (change requires restart)
|
||||
#password_encryption = on
|
||||
#db_user_namespace = off
|
||||
#row_security = on
|
||||
|
||||
# GSSAPI using Kerberos
|
||||
#krb_server_keyfile = ''
|
||||
#krb_caseins_users = off
|
||||
|
||||
# - TCP Keepalives -
|
||||
# see "man 7 tcp" for details
|
||||
|
||||
#tcp_keepalives_idle = 0 # TCP_KEEPIDLE, in seconds;
|
||||
# 0 selects the system default
|
||||
#tcp_keepalives_interval = 0 # TCP_KEEPINTVL, in seconds;
|
||||
# 0 selects the system default
|
||||
#tcp_keepalives_count = 0 # TCP_KEEPCNT;
|
||||
# 0 selects the system default
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# RESOURCE USAGE (except WAL)
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Memory -
|
||||
# Recommended 75 % of the database memory
|
||||
shared_buffers = 512MB # min 128kB
|
||||
# (change requires restart)
|
||||
#huge_pages = try # on, off, or try
|
||||
# (change requires restart)
|
||||
#temp_buffers = 8MB # min 800kB
|
||||
#max_prepared_transactions = 0 # zero disables the feature
|
||||
# (change requires restart)
|
||||
# Caution: it is not advisable to set max_prepared_transactions nonzero unless
|
||||
# you actively intend to use prepared transactions.
|
||||
work_mem = 16MB # min 64kB
|
||||
maintenance_work_mem = 128MB # min 1MB
|
||||
#replacement_sort_tuples = 150000 # limits use of replacement selection sort
|
||||
#autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem
|
||||
#max_stack_depth = 2MB # min 100kB
|
||||
dynamic_shared_memory_type = posix # the default is the first option
|
||||
# supported by the operating system:
|
||||
# posix
|
||||
# sysv
|
||||
# windows
|
||||
# mmap
|
||||
# use none to disable dynamic shared memory
|
||||
# (change requires restart)
|
||||
|
||||
# - Disk -
|
||||
|
||||
#temp_file_limit = -1 # limits per-process temp file space
|
||||
# in kB, or -1 for no limit
|
||||
|
||||
# - Kernel Resource Usage -
|
||||
|
||||
#max_files_per_process = 1000 # min 25
|
||||
# (change requires restart)
|
||||
#shared_preload_libraries = '' # (change requires restart)
|
||||
|
||||
# - Cost-Based Vacuum Delay -
|
||||
|
||||
#vacuum_cost_delay = 0 # 0-100 milliseconds
|
||||
#vacuum_cost_page_hit = 1 # 0-10000 credits
|
||||
#vacuum_cost_page_miss = 10 # 0-10000 credits
|
||||
#vacuum_cost_page_dirty = 20 # 0-10000 credits
|
||||
#vacuum_cost_limit = 200 # 1-10000 credits
|
||||
|
||||
# - Background Writer -
|
||||
|
||||
#bgwriter_delay = 200ms # 10-10000ms between rounds
|
||||
#bgwriter_lru_maxpages = 100 # 0-1000 max buffers written/round
|
||||
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
|
||||
#bgwriter_flush_after = 512kB # measured in pages, 0 disables
|
||||
|
||||
# - Asynchronous Behavior -
|
||||
|
||||
#effective_io_concurrency = 1 # 1-1000; 0 disables prefetching
|
||||
max_worker_processes = 8 # (change requires restart)
|
||||
max_parallel_workers_per_gather = 2 # taken from max_worker_processes
|
||||
#old_snapshot_threshold = -1 # 1min-60d; -1 disables; 0 is immediate
|
||||
# (change requires restart)
|
||||
#backend_flush_after = 0 # measured in pages, 0 disables
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# WRITE AHEAD LOG
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Settings -
|
||||
|
||||
#wal_level = minimal # minimal, replica, or logical
|
||||
# (change requires restart)
|
||||
#fsync = on # flush data to disk for crash safety
|
||||
# (turning this off can cause
|
||||
# unrecoverable data corruption)
|
||||
#synchronous_commit = on # synchronization level;
|
||||
# off, local, remote_write, remote_apply, or on
|
||||
#wal_sync_method = fsync # the default is the first option
|
||||
# supported by the operating system:
|
||||
# open_datasync
|
||||
# fdatasync (default on Linux)
|
||||
# fsync
|
||||
# fsync_writethrough
|
||||
# open_sync
|
||||
#full_page_writes = on # recover from partial page writes
|
||||
#wal_compression = off # enable compression of full-page writes
|
||||
#wal_log_hints = off # also do full page writes of non-critical updates
|
||||
# (change requires restart)
|
||||
wal_buffers = 1 # min 32kB, -1 sets based on shared_buffers
|
||||
# (change requires restart)
|
||||
#wal_writer_delay = 200ms # 1-10000 milliseconds
|
||||
#wal_writer_flush_after = 1MB # measured in pages, 0 disables
|
||||
|
||||
#commit_delay = 0 # range 0-100000, in microseconds
|
||||
#commit_siblings = 5 # range 1-1000
|
||||
|
||||
# - Checkpoints -
|
||||
|
||||
#checkpoint_timeout = 5min # range 30s-1d
|
||||
#max_wal_size = 1GB
|
||||
#min_wal_size = 80MB
|
||||
#checkpoint_completion_target = 0.5 # checkpoint target duration, 0.0 - 1.0
|
||||
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
|
||||
#checkpoint_warning = 30s # 0 disables
|
||||
|
||||
# - Archiving -
|
||||
|
||||
#archive_mode = off # enables archiving; off, on, or always
|
||||
# (change requires restart)
|
||||
#archive_command = ''
|
||||
# placeholders: %p = path of file to archive
|
||||
# %f = file name only
|
||||
# e.g. 'test ! -f /opt/archivedir/%f && cp %p /opt/archivedir/%f'
|
||||
#archive_timeout = 0 # force a logfile segment switch after this
|
||||
# number of seconds; 0 disables
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# REPLICATION
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Sending Server(s) -
|
||||
|
||||
# Set these on the master and on any standby that will send replication data.
|
||||
|
||||
max_wal_senders = 8 # max number of walsender processes
|
||||
# (change requires restart)
|
||||
wal_keep_segments = 100 # in logfile segments, 16MB each; 0 disables
|
||||
#wal_sender_timeout = 60s # in milliseconds; 0 disables
|
||||
|
||||
#max_replication_slots = 0 # max number of replication slots
|
||||
# (change requires restart)
|
||||
#track_commit_timestamp = off # collect timestamp of transaction commit
|
||||
# (change requires restart)
|
||||
|
||||
# - Master Server -
|
||||
|
||||
# These settings are ignored on a standby server.
|
||||
|
||||
#synchronous_standby_names = '' # standby servers that provide sync rep
|
||||
# number of sync standbys and comma-separated list of application_name
|
||||
# from standby(s); '*' = all
|
||||
#vacuum_defer_cleanup_age = 0 # number of xacts by which cleanup is delayed
|
||||
|
||||
# - Standby Servers -
|
||||
|
||||
# These settings are ignored on a master server.
|
||||
|
||||
#hot_standby = off # "on" allows queries during recovery
|
||||
# (change requires restart)
|
||||
#max_standby_archive_delay = 30s # max delay before canceling queries
|
||||
# when reading WAL from archive;
|
||||
# -1 allows indefinite delay
|
||||
#max_standby_streaming_delay = 30s # max delay before canceling queries
|
||||
# when reading streaming WAL;
|
||||
# -1 allows indefinite delay
|
||||
#wal_receiver_status_interval = 10s # send replies at least this often
|
||||
# 0 disables
|
||||
#hot_standby_feedback = off # send info from standby to prevent
|
||||
# query conflicts
|
||||
#wal_receiver_timeout = 60s # time that receiver waits for
|
||||
# communication from master
|
||||
# in milliseconds; 0 disables
|
||||
#wal_retrieve_retry_interval = 5s # time to wait before retrying to
|
||||
# retrieve WAL after a failed attempt
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# QUERY TUNING
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Planner Method Configuration -
|
||||
|
||||
#enable_bitmapscan = on
|
||||
#enable_hashagg = on
|
||||
#enable_hashjoin = on
|
||||
#enable_indexscan = on
|
||||
#enable_indexonlyscan = on
|
||||
#enable_material = on
|
||||
#enable_mergejoin = on
|
||||
#enable_nestloop = on
|
||||
#enable_seqscan = on
|
||||
#enable_sort = on
|
||||
#enable_tidscan = on
|
||||
|
||||
# - Planner Cost Constants -
|
||||
|
||||
seq_page_cost = 1.0 # measured on an arbitrary scale
|
||||
random_page_cost = 2.0 # same scale as above
|
||||
#cpu_tuple_cost = 0.01 # same scale as above
|
||||
#cpu_index_tuple_cost = 0.005 # same scale as above
|
||||
#cpu_operator_cost = 0.0025 # same scale as above
|
||||
#parallel_tuple_cost = 0.1 # same scale as above
|
||||
#parallel_setup_cost = 1000.0 # same scale as above
|
||||
#min_parallel_relation_size = 8MB
|
||||
effective_cache_size = 512MB
|
||||
|
||||
# - Genetic Query Optimizer -
|
||||
|
||||
#geqo = on
|
||||
#geqo_threshold = 12
|
||||
#geqo_effort = 5 # range 1-10
|
||||
#geqo_pool_size = 0 # selects default based on effort
|
||||
#geqo_generations = 0 # selects default based on effort
|
||||
#geqo_selection_bias = 2.0 # range 1.5-2.0
|
||||
#geqo_seed = 0.0 # range 0.0-1.0
|
||||
|
||||
# - Other Planner Options -
|
||||
|
||||
#default_statistics_target = 100 # range 1-10000
|
||||
#constraint_exclusion = partition # on, off, or partition
|
||||
#cursor_tuple_fraction = 0.1 # range 0.0-1.0
|
||||
#from_collapse_limit = 8
|
||||
#join_collapse_limit = 8 # 1 disables collapsing of explicit
|
||||
# JOIN clauses
|
||||
#force_parallel_mode = off
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR REPORTING AND LOGGING
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Where to Log -
|
||||
|
||||
#log_destination = 'stderr' # Valid values are combinations of
|
||||
# stderr, csvlog, syslog, and eventlog,
|
||||
# depending on platform. csvlog
|
||||
# requires logging_collector to be on.
|
||||
|
||||
# This is used when logging to stderr:
|
||||
#logging_collector = off # Enable capturing of stderr and csvlog
|
||||
# into log files. Required to be on for
|
||||
# csvlogs.
|
||||
# (change requires restart)
|
||||
|
||||
# These are only used if logging_collector is on:
|
||||
#log_directory = 'pg_log' # directory where log files are written,
|
||||
# can be absolute or relative to PGDATA
|
||||
#log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' # log file name pattern,
|
||||
# can include strftime() escapes
|
||||
#log_file_mode = 0600 # creation mode for log files,
|
||||
# begin with 0 to use octal notation
|
||||
#log_truncate_on_rotation = off # If on, an existing log file with the
|
||||
# same name as the new log file will be
|
||||
# truncated rather than appended to.
|
||||
# But such truncation only occurs on
|
||||
# time-driven rotation, not on restarts
|
||||
# or size-driven rotation. Default is
|
||||
# off, meaning append to existing files
|
||||
# in all cases.
|
||||
#log_rotation_age = 1d # Automatic rotation of logfiles will
|
||||
# happen after that time. 0 disables.
|
||||
#log_rotation_size = 10MB # Automatic rotation of logfiles will
|
||||
# happen after that much log output.
|
||||
# 0 disables.
|
||||
|
||||
# These are relevant when logging to syslog:
|
||||
#syslog_facility = 'LOCAL0'
|
||||
#syslog_ident = 'postgres'
|
||||
#syslog_sequence_numbers = on
|
||||
#syslog_split_messages = on
|
||||
|
||||
# This is only relevant when logging to eventlog (win32):
|
||||
# (change requires restart)
|
||||
#event_source = 'PostgreSQL'
|
||||
|
||||
# - When to Log -
|
||||
|
||||
#client_min_messages = notice # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# log
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
|
||||
#log_min_messages = warning # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic
|
||||
|
||||
#log_min_error_statement = error # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic (effectively off)
|
||||
|
||||
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
|
||||
# and their durations, > 0 logs only
|
||||
# statements running at least this number
|
||||
# of milliseconds
|
||||
|
||||
|
||||
# - What to Log -
|
||||
|
||||
#debug_print_parse = off
|
||||
#debug_print_rewritten = off
|
||||
#debug_print_plan = off
|
||||
#debug_pretty_print = on
|
||||
#log_checkpoints = off
|
||||
#log_connections = off
|
||||
#log_disconnections = off
|
||||
#log_duration = off
|
||||
#log_error_verbosity = default # terse, default, or verbose messages
|
||||
#log_hostname = off
|
||||
log_line_prefix = '%m [%p] %q%u@%d ' # special values:
|
||||
# %a = application name
|
||||
# %u = user name
|
||||
# %d = database name
|
||||
# %r = remote host and port
|
||||
# %h = remote host
|
||||
# %p = process ID
|
||||
# %t = timestamp without milliseconds
|
||||
# %m = timestamp with milliseconds
|
||||
# %n = timestamp with milliseconds (as a Unix epoch)
|
||||
# %i = command tag
|
||||
# %e = SQL state
|
||||
# %c = session ID
|
||||
# %l = session line number
|
||||
# %s = session start timestamp
|
||||
# %v = virtual transaction ID
|
||||
# %x = transaction ID (0 if none)
|
||||
# %q = stop here in non-session
|
||||
# processes
|
||||
# %% = '%'
|
||||
# e.g. '<%u%%%d> '
|
||||
#log_lock_waits = off # log lock waits >= deadlock_timeout
|
||||
#log_statement = 'none' # none, ddl, mod, all
|
||||
#log_replication_commands = off
|
||||
#log_temp_files = -1 # log temporary files equal or larger
|
||||
# than the specified size in kilobytes;
|
||||
# -1 disables, 0 logs all temp files
|
||||
log_timezone = 'UTC'
|
||||
|
||||
|
||||
# - Process Title -
|
||||
|
||||
cluster_name = '10.0/main' # added to process titles if nonempty
|
||||
# (change requires restart)
|
||||
#update_process_title = on
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# RUNTIME STATISTICS
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Query/Index Statistics Collector -
|
||||
|
||||
#track_activities = on
|
||||
#track_counts = on
|
||||
#track_io_timing = off
|
||||
#track_functions = none # none, pl, all
|
||||
#track_activity_query_size = 1024 # (change requires restart)
|
||||
stats_temp_directory = '/var/run/postgresql/'
|
||||
|
||||
|
||||
# - Statistics Monitoring -
|
||||
|
||||
#log_parser_stats = off
|
||||
#log_planner_stats = off
|
||||
#log_executor_stats = off
|
||||
#log_statement_stats = off
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# AUTOVACUUM PARAMETERS
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
#autovacuum = on # Enable autovacuum subprocess? 'on'
|
||||
# requires track_counts to also be on.
|
||||
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
|
||||
# their durations, > 0 logs only
|
||||
# actions running at least this number
|
||||
# of milliseconds.
|
||||
#autovacuum_max_workers = 3 # max number of autovacuum subprocesses
|
||||
# (change requires restart)
|
||||
#autovacuum_naptime = 1min # time between autovacuum runs
|
||||
#autovacuum_vacuum_threshold = 50 # min number of row updates before
|
||||
# vacuum
|
||||
#autovacuum_analyze_threshold = 50 # min number of row updates before
|
||||
# analyze
|
||||
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
|
||||
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
|
||||
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
|
||||
# (change requires restart)
|
||||
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
|
||||
# before forced vacuum
|
||||
# (change requires restart)
|
||||
#autovacuum_vacuum_cost_delay = 20ms # default vacuum cost delay for
|
||||
# autovacuum, in milliseconds;
|
||||
# -1 means use vacuum_cost_delay
|
||||
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
|
||||
# autovacuum, -1 means use
|
||||
# vacuum_cost_limit
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# CLIENT CONNECTION DEFAULTS
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Statement Behavior -
|
||||
|
||||
#search_path = '"$user", public' # schema names
|
||||
#default_tablespace = '' # a tablespace name, '' uses the default
|
||||
#temp_tablespaces = '' # a list of tablespace names, '' uses
|
||||
# only default tablespace
|
||||
#check_function_bodies = on
|
||||
#default_transaction_isolation = 'read committed'
|
||||
#default_transaction_read_only = off
|
||||
#default_transaction_deferrable = off
|
||||
#session_replication_role = 'origin'
|
||||
#statement_timeout = 0 # in milliseconds, 0 is disabled
|
||||
#lock_timeout = 0 # in milliseconds, 0 is disabled
|
||||
#idle_in_transaction_session_timeout = 0 # in milliseconds, 0 is disabled
|
||||
#vacuum_freeze_min_age = 50000000
|
||||
#vacuum_freeze_table_age = 150000000
|
||||
#vacuum_multixact_freeze_min_age = 5000000
|
||||
#vacuum_multixact_freeze_table_age = 150000000
|
||||
#bytea_output = 'hex' # hex, escape
|
||||
#xmlbinary = 'base64'
|
||||
xmloption = 'document'
|
||||
#gin_fuzzy_search_limit = 0
|
||||
#gin_pending_list_limit = 4MB
|
||||
|
||||
# - Locale and Formatting -
|
||||
|
||||
datestyle = 'iso, mdy'
|
||||
#intervalstyle = 'postgres'
|
||||
timezone = 'UTC'
|
||||
#timezone_abbreviations = 'Default' # Select the set of available time zone
|
||||
# abbreviations. Currently, there are
|
||||
# Default
|
||||
# Australia (historical usage)
|
||||
# India
|
||||
# You can create your own file in
|
||||
# share/timezonesets/.
|
||||
#extra_float_digits = 0 # min -15, max 3
|
||||
#client_encoding = sql_ascii # actually, defaults to database
|
||||
# encoding
|
||||
|
||||
# These settings are initialized by initdb, but they can be changed.
|
||||
lc_messages = 'C.UTF-8' # locale for system error message
|
||||
# strings
|
||||
lc_monetary = 'C.UTF-8' # locale for monetary formatting
|
||||
lc_numeric = 'C.UTF-8' # locale for number formatting
|
||||
lc_time = 'C.UTF-8' # locale for time formatting
|
||||
|
||||
# default configuration for text search
|
||||
default_text_search_config = 'pg_catalog.english'
|
||||
|
||||
# - Other Defaults -
|
||||
|
||||
#dynamic_library_path = '$libdir'
|
||||
#local_preload_libraries = ''
|
||||
#session_preload_libraries = ''
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# LOCK MANAGEMENT
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
#deadlock_timeout = 1s
|
||||
#max_locks_per_transaction = 64 # min 10
|
||||
# (change requires restart)
|
||||
#max_pred_locks_per_transaction = 64 # min 10
|
||||
# (change requires restart)
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# VERSION/PLATFORM COMPATIBILITY
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# - Previous PostgreSQL Versions -
|
||||
|
||||
#array_nulls = on
|
||||
#backslash_quote = safe_encoding # on, off, or safe_encoding
|
||||
#default_with_oids = off
|
||||
#escape_string_warning = on
|
||||
#lo_compat_privileges = off
|
||||
#operator_precedence_warning = off
|
||||
#quote_all_identifiers = off
|
||||
#sql_inheritance = on
|
||||
#standard_conforming_strings = on
|
||||
#synchronize_seqscans = on
|
||||
|
||||
# - Other Platforms and Clients -
|
||||
|
||||
#transform_null_equals = off
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR HANDLING
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
#exit_on_error = off # terminate session on any error?
|
||||
#restart_after_crash = on # reinitialize after backend crash?
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# CONFIG FILE INCLUDES
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# These options allow settings to be loaded from files other than the
|
||||
# default postgresql.conf.
|
||||
|
||||
include_dir = 'conf.d' # include files ending in '.conf' from
|
||||
# directory 'conf.d'
|
||||
#include_if_exists = 'exists.conf' # include file only if it exists
|
||||
#include = 'special.conf' # include file
|
||||
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# CUSTOMIZED OPTIONS
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
# Add settings for extensions here
|
||||
listen_addresses = '*'
|
||||
port = 5432
|
||||
ssl = true
|
||||
ssl_cert_file = '/etc/ssl/certs/ssl-cert-snakeoil.pem'
|
||||
ssl_key_file = '/etc/ssl/private/ssl-cert-snakeoil.key'
|
||||
wal_level = hot_standby
|
||||
max_wal_senders = 8
|
||||
wal_keep_segments = 100
|
||||
hot_standby = on
|
||||
|
|
@ -7,9 +7,27 @@ source /env-data.sh
|
|||
# Refresh configuration in case environment settings changed.
|
||||
cat $CONF.template > $CONF
|
||||
|
||||
# This script will setup necessary configuration to optimise for PostGIS and to enable replications
|
||||
cat >> $CONF <<EOF
|
||||
wal_level = hot_standby
|
||||
max_wal_senders = $PG_MAX_WAL_SENDERS
|
||||
wal_keep_segments = $PG_WAL_KEEP_SEGMENTS
|
||||
hot_standby = on
|
||||
listen_addresses = '${IP_LIST}'
|
||||
shared_buffers = 500MB
|
||||
work_mem = 16MB
|
||||
maintenance_work_mem = 128MB
|
||||
wal_buffers = 1MB
|
||||
# uncomment checkpoint_segments below if postgresql <= 9.4
|
||||
# checkpoint_segments = 6
|
||||
random_page_cost = 2.0
|
||||
xmloption = 'document'
|
||||
#archive_mode=on
|
||||
#archive_command = 'test ! -f ${WAL_ARCHIVE}/%f && cp -r %p ${WAL_ARCHIVE}/%f'
|
||||
EOF
|
||||
|
||||
# Optimise PostgreSQL shared memory for PostGIS
|
||||
# shmall units are pages and shmmax units are bytes(?) equivalent to the desired shared_buffer size set in setup_conf.sh - in this case 500MB
|
||||
echo "kernel.shmmax=543252480" >> /etc/sysctl.conf
|
||||
echo "kernel.shmall=2097152" >> /etc/sysctl.conf
|
||||
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ fi
|
|||
trap "echo \"Sending SIGTERM to postgres\"; killall -s SIGTERM postgres" SIGTERM
|
||||
echo "Use modified postgresql.conf for greater speed (spatial and replication)"
|
||||
|
||||
cat /tmp/postgresql.conf > ${CONF}
|
||||
|
||||
|
||||
su - postgres -c "${POSTGRES} -D ${DATADIR} -c config_file=${CONF} ${LOCALONLY} &"
|
||||
|
||||
|
|
|
|||
Ładowanie…
Reference in New Issue