|
|
||
|---|---|---|
| .github/workflows | ||
| docs | ||
| scripts | ||
| src | ||
| .dockerignore | ||
| .gitignore | ||
| Dockerfile | ||
| LICENSE | ||
| Pipfile | ||
| Pipfile.lock | ||
| README.md | ||
| example.orchestration.yaml | ||
| pyproject.toml | ||
| setup.cfg | ||
| setup.py | ||
README.md
Auto Archiver
![]()

Read the article about Auto Archiver on bellingcat.com.
Python tool to automatically archive social media posts, videos, and images from a Google Sheets, the console, and more. Uses different archivers depending on the platform, and can save content to local storage, S3 bucket (Digital Ocean Spaces, AWS, ...), and Google Drive. If using Google Sheets as the source for links, it will be updated with information about the archived content. It can be run manually or on an automated basis.
There are 3 ways to use the auto-archiver:
- (easiest installation) via docker
- (local python install)
pip install auto-archiver - (legacy/development) clone and manually install from repo (see legacy tutorial video)
But you always need a configuration/orchestration file, which is where you'll configure where/what/how to archive. Make sure you read orchestration.
How to install and run the auto-archiver
Option 1 - docker

Docker works like a virtual machine running inside your computer, it isolates everything and makes installation simple. Since it is an isolated environment when you need to pass it your orchestration file or get downloaded media out of docker you will need to connect folders on your machine with folders inside docker with the -v volume flag.
- install docker
- pull the auto-archiver docker image with
docker pull bellingcat/auto-archiver - run the docker image locally in a container:
docker run --rm -v $PWD/secrets:/app/secrets -v $PWD/local_archive:/app/local_archive bellingcat/auto-archiver --config secrets/orchestration.yamlbreaking this command down:docker runtells docker to start a new container (an instance of the image)--rmmakes sure this container is removed after execution (less garbage locally)-v $PWD/secrets:/app/secrets- your secrets folder-vis a volume flag which means a folder that you have on your computer will be connected to a folder inside the docker container$PWD/secretspoints to asecrets/folder in your current working directory (where your console points to), we use this folder as a best practice to hold all the secrets/tokens/passwords/... you use/app/secretspoints to the path the docker container where this image can be found
-v $PWD/local_archive:/app/local_archive- (optional) if you use local_storage-vsame as above, this is a volume instruction$PWD/local_archiveis a folderlocal_archive/in case you want to archive locally and have the files accessible outside docker/app/local_archiveis a folder inside docker that you can reference in your orchestration.yml file
Option 2 - python package
Python package instructions
- make sure you have python 3.10 or higher installed
- install the package
pip/pipenv/conda install auto-archiver - test it's installed with
auto-archiver --help - run it with your orchestration file and pass any flags you want in the command line
auto-archiver --config secrets/orchestration.yamlif your orchestration file is inside asecrets/, which we advise
You will also need ffmpeg, firefox and geckodriver, and optionally fonts-noto. Similar to the local installation.
Option 3 - local installation
This can also be used for development.
Legacy instructions, only use if docker/package is not an option
Install the following locally:
- ffmpeg must also be installed locally for this tool to work.
- firefox and geckodriver on a path folder like
/usr/local/bin. - (optional) fonts-noto to deal with multiple unicode characters during selenium/geckodriver's screenshots:
sudo apt install fonts-noto -y.
Clone and run:
git clone https://github.com/bellingcat/auto-archiverpipenv installpipenv run python -m src.auto_archiver --config secrets/orchestration.yaml
Orchestration
The archiver work is orchestrated by the following workflow (we call each a step):
- Feeder gets the links (from a spreadsheet, from the console, ...)
- Archiver tries to archive the link (twitter, youtube, ...)
- Enricher adds more info to the content (hashes, thumbnails, ...)
- Formatter creates a report from all the archived content (HTML, PDF, ...)
- Database knows what's been archived and also stores the archive result (spreadsheet, CSV, or just the console)
To setup an auto-archiver instance create an orchestration.yaml which contains the workflow you would like. We advise you put this file into a secrets/ folder and do not share it with others because it will contain passwords and other secrets.
The structure of orchestration file is split into 2 parts: steps (what steps to use) and configurations (how those steps should behave), here's a simplification:
# orchestration.yaml content
steps:
feeder: gsheet_feeder
archivers: # order matters
- youtubedl_archiver
enrichers:
- thumbnail_enricher
formatter: html_formatter
storages:
- local_storage
databases:
- gsheet_db
configurations:
gsheet_feeder:
sheet: "your google sheet name"
header: 2 # row with header for your sheet
# ... configurations for the other steps here ...
To see all available steps (which archivers, storages, databases, ...) exist check the example.orchestration.yaml.
All the configurations in the orchestration.yaml file (you can name it differently but need to pass it in the --config FILENAME argument) can be seen in the console by using the --help flag. They can also be overwritten, for example if you are using the cli_feeder to archive from the command line and want to provide the URLs you should do:
auto-archiver --config secrets/orchestration.yaml --cli_feeder.urls="url1,url2,url3"
Here's the complete workflow that the auto-archiver goes through:
graph TD
s((start)) --> F(fa:fa-table Feeder)
F -->|get and clean URL| D1{fa:fa-database Database}
D1 -->|is already archived| e((end))
D1 -->|not yet archived| a(fa:fa-download Archivers)
a -->|got media| E(fa:fa-chart-line Enrichers)
E --> S[fa:fa-box-archive Storages]
E --> Fo(fa:fa-code Formatter)
Fo --> S
Fo -->|update database| D2(fa:fa-database Database)
D2 --> e
Orchestration checklist
Use this to make sure you help making sure you did all the required steps:
- you have a
/secretsfolder with all your configuration files including- a orchestration file eg:
orchestration.yamlpointing to the correct location of other files - (optional if you use GoogleSheets) you have a
service_account.json(see how-to) - (optional for telegram) a
anon.sessionwhich appears after the 1st run where you login to telegram- if you use private channels you need to add
channel_invitesand setjoin_channels=trueat least once
- if you use private channels you need to add
- (optional for VK) a
vk_config.v2.json - (optional for using GoogleDrive storage)
gd-token.json(see help script) - (optional for instagram)
instaloader.sessionfile which appears after the 1st run and login in instagram - (optional for browsertrix)
profile.tar.gzfile
- a orchestration file eg:
Example invocations
The recommended way to run the auto-archiver is through Docker. The invocations below will run the auto-archiver Docker image using a configuration file that you have specified
# all the configurations come from ./secrets/orchestration.yaml
docker run --rm -v $PWD/secrets:/app/secrets -v $PWD/local_archive:/app/local_archive bellingcat/auto-archiver --config secrets/orchestration.yaml
# uses the same configurations but for another google docs sheet
# with a header on row 2 and with some different column names
# notice that columns is a dictionary so you need to pass it as JSON and it will override only the values provided
docker run --rm -v $PWD/secrets:/app/secrets -v $PWD/local_archive:/app/local_archive bellingcat/auto-archiver --config secrets/orchestration.yaml --gsheet_feeder.sheet="use it on another sheets doc" --gsheet_feeder.header=2 --gsheet_feeder.columns='{"url": "link"}'
# all the configurations come from orchestration.yaml and specifies that s3 files should be private
docker run --rm -v $PWD/secrets:/app/secrets -v $PWD/local_archive:/app/local_archive bellingcat/auto-archiver --config secrets/orchestration.yaml --s3_storage.private=1
The auto-archiver can also be run locally, if pre-requisites are correctly configured. Equivalent invocations are below.
# all the configurations come from ./secrets/orchestration.yaml
auto-archiver --config secrets/orchestration.yaml
# uses the same configurations but for another google docs sheet
# with a header on row 2 and with some different column names
# notice that columns is a dictionary so you need to pass it as JSON and it will override only the values provided
auto-archiver --config secrets/orchestration.yaml --gsheet_feeder.sheet="use it on another sheets doc" --gsheet_feeder.header=2 --gsheet_feeder.columns='{"url": "link"}'
# all the configurations come from orchestration.yaml and specifies that s3 files should be private
auto-archiver --config secrets/orchestration.yaml --s3_storage.private=1
Extra notes on configuration
Google Drive
To use Google Drive storage you need the id of the shared folder in the config.yaml file which must be shared with the service account eg autoarchiverservice@auto-archiver-111111.iam.gserviceaccount.com and then you can use --storage=gd
Telethon + Instagram with telegram bot
The first time you run, you will be prompted to do a authentication with the phone number associated, alternatively you can put your anon.session in the root.
Atlos
When integrating with Atlos, you will need to provide an API token in your configuration. You can learn more about Atlos and how to get an API token here. You will have to provide this token to the atlos_feeder, atlos_storage, and atlos_db steps in your orchestration file. If you use a custom or self-hosted Atlos instance, you can also specify the atlos_url option to point to your custom instance's URL. For example:
# orchestration.yaml content
steps:
feeder: atlos_feeder
archivers: # order matters
- youtubedl_archiver
enrichers:
- thumbnail_enricher
- hash_enricher
formatter: html_formatter
storages:
- atlos_storage
databases:
- console_db
- atlos_db
configurations:
atlos_feeder:
atlos_url: "https://platform.atlos.org" # optional
api_token: "...your API token..."
atlos_db:
atlos_url: "https://platform.atlos.org" # optional
api_token: "...your API token..."
atlos_storage:
atlos_url: "https://platform.atlos.org" # optional
api_token: "...your API token..."
hash_enricher:
algorithm: "SHA-256"
Running on Google Sheets Feeder (gsheet_feeder)
The --gsheet_feeder.sheet property is the name of the Google Sheet to check for URLs.
This sheet must have been shared with the Google Service account used by gspread.
This sheet must also have specific columns (case-insensitive) in the header as specified in Gsheet.configs. The default names of these columns and their purpose is:
Inputs:
- Link (required): the URL of the post to archive
- Destination folder: custom folder for archived file (regardless of storage)
Outputs:
- Archive status (required): Status of archive operation
- Archive location: URL of archived post
- Archive date: Date archived
- Thumbnail: Embeds a thumbnail for the post in the spreadsheet
- Timestamp: Timestamp of original post
- Title: Post title
- Text: Post text
- Screenshot: Link to screenshot of post
- Hash: Hash of archived HTML file (which contains hashes of post media) - for checksums/verification
- Perceptual Hash: Perceptual hashes of found images - these can be used for de-duplication of content
- WACZ: Link to a WACZ web archive of post
- ReplayWebpage: Link to a ReplayWebpage viewer of the WACZ archive
For example, this is a spreadsheet configured with all of the columns for the auto archiver and a few URLs to archive. (Note that the column names are not case sensitive.)
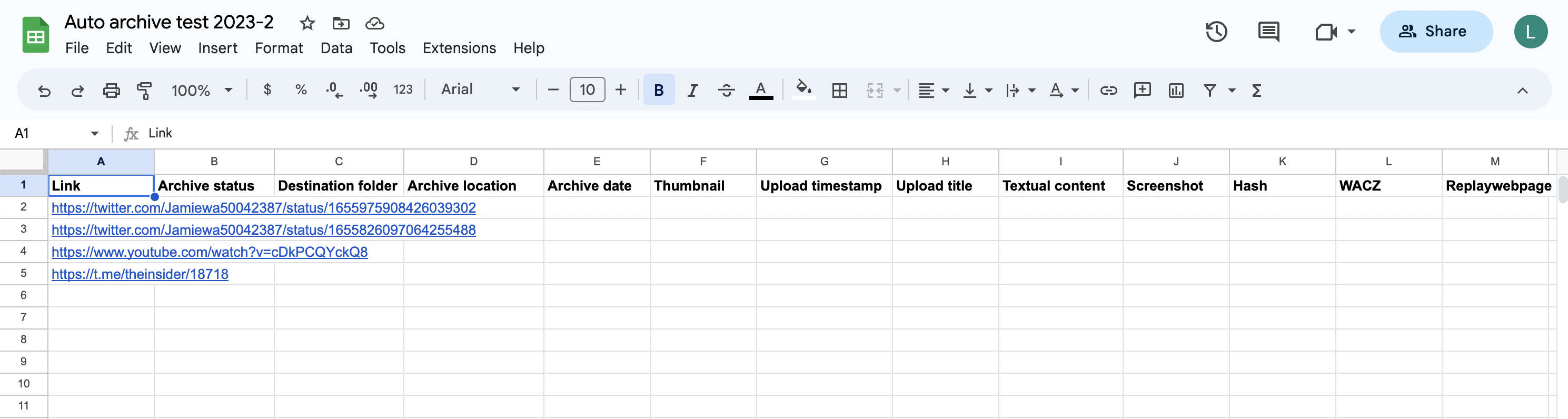
Now the auto archiver can be invoked, with this command in this example: docker run --rm -v $PWD/secrets:/app/secrets -v $PWD/local_archive:/app/local_archive bellingcat/auto-archiver:dockerize --config secrets/orchestration-global.yaml --gsheet_feeder.sheet "Auto archive test 2023-2". Note that the sheet name has been overridden/specified in the command line invocation.
When the auto archiver starts running, it updates the "Archive status" column.
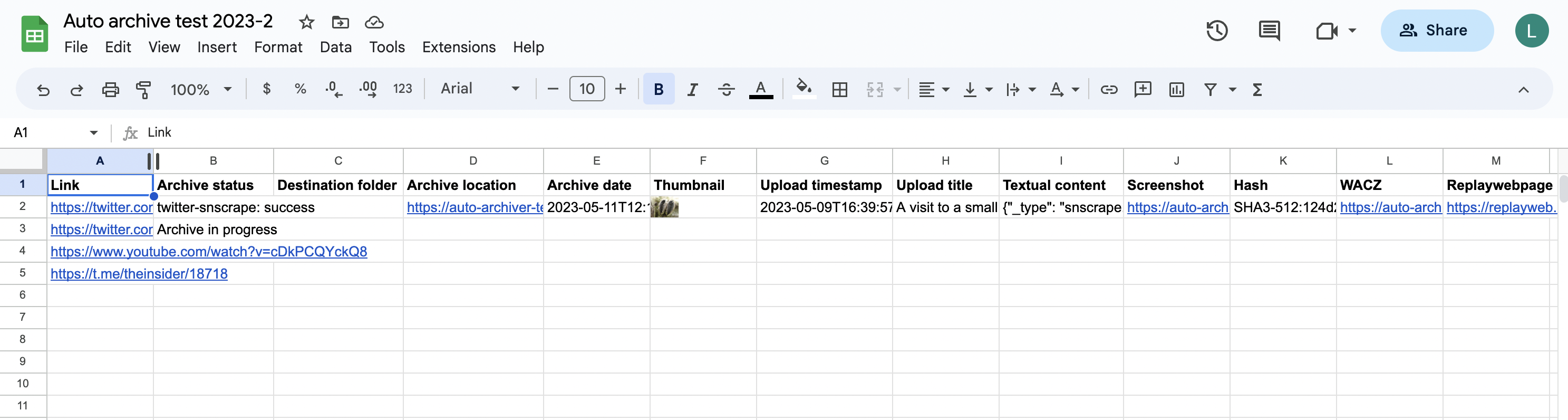
The links are downloaded and archived, and the spreadsheet is updated to the following:

Note that the first row is skipped, as it is assumed to be a header row (--gsheet_feeder.header=1 and you can change it if you use more rows above). Rows with an empty URL column, or a non-empty archive column are also skipped. All sheets in the document will be checked.
The "archive location" link contains the path of the archived file, in local storage, S3, or in Google Drive.
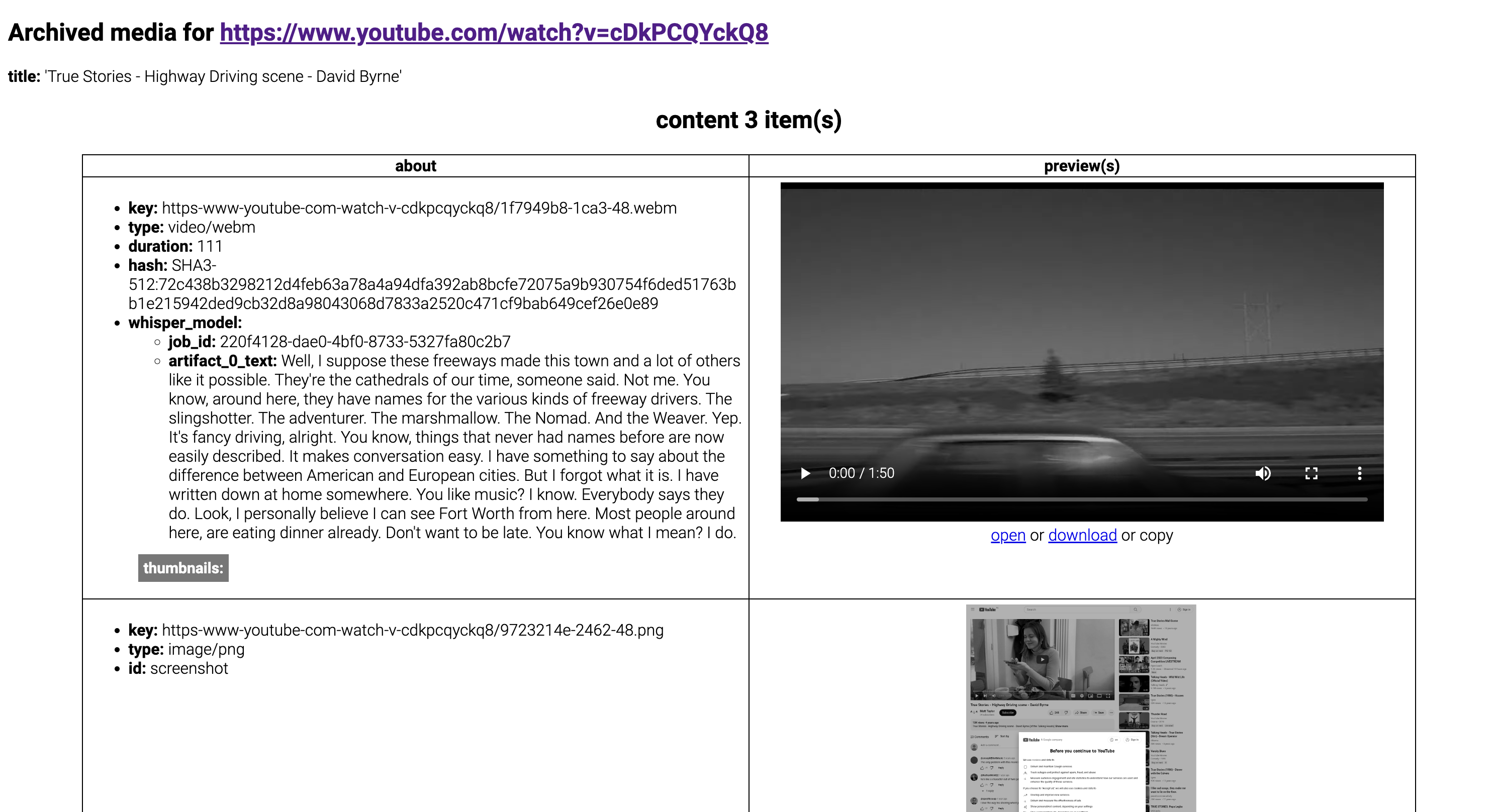
Development
Use python -m src.auto_archiver --config secrets/orchestration.yaml to run from the local development environment.
Docker development
working with docker locally:
docker build . -t auto-archiverto build a local imagedocker run --rm -v $PWD/secrets:/app/secrets auto-archiver --config secrets/orchestration.yaml- to use local archive, also create a volume
-vfor it by adding-v $PWD/local_archive:/app/local_archive
- to use local archive, also create a volume
manual release to docker hub
docker image tag auto-archiver bellingcat/auto-archiver:latestdocker push bellingcat/auto-archiver
RELEASE
- update version in version.py
- go to github releases > new release > use
vx.y.zfor matching version notation- package is automatically updated in pypi
- docker image is automatically pushed to dockerhup